Backpropagation with Scalar Calculus
In this chapter lets deep dive a bit more into the technique of Back Propagation
How Backpropagation Works
Consider a neural network with multiple layers. The weight of layer $l$ is $W^l$. And for the previous layer it is $W^{(l-1)}$.
The best way to understand backpropagation is visually and by the way it is done by the tree representation of 3Blue1Brown video linked here.
The below GIF is a representation of a single path in the last layer($l$ of a neural network; and it shows how the connection from previous layer - that is the activation of the previous layer and the weight of the current layer is affecting the output; and thereby the final Cost.
The central idea is how a small change in weight in the previous layer affects the final output of the network.
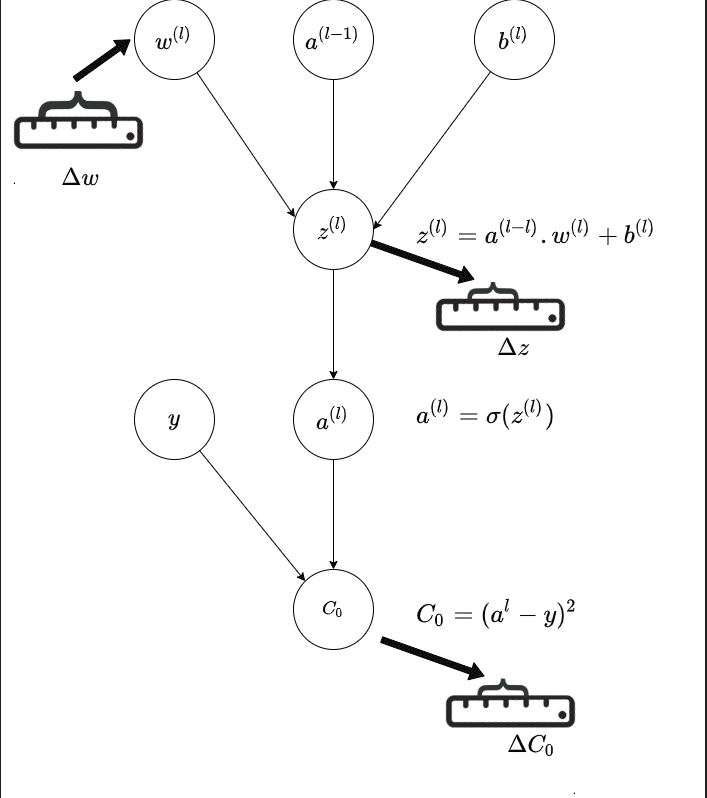 Source : Author
Source : Author
Writing This Out as Chain Rule
Here is a more detailed depiction of how the small change in weight adds through the chain to affect the final cost, and how much the small change of weight in an inner layer affect the final cost.
This is the Chain Rule of Calculus and the diagram is trying to illustrate that visually via a chain of activations, via a Computational Graph
\[\frac{\partial C_0}{\partial W^l} = \frac{\partial C_0}{\partial a^l} \cdot \frac{\partial a^l}{\partial z^l} \cdot \frac{\partial z^l}{\partial W^l}\]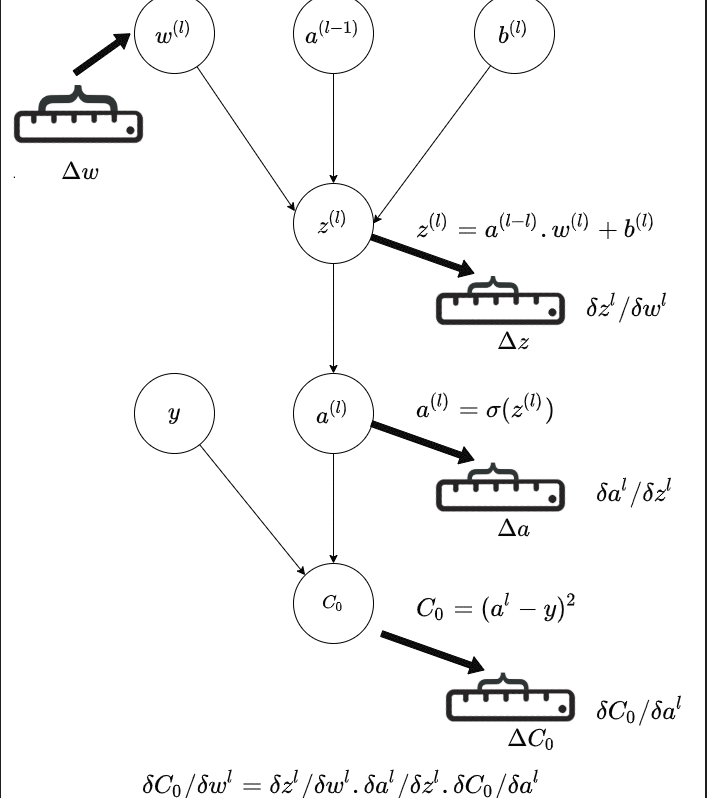 Source : Author
Source : Author
Next part of the recipe is adjusting the weights of each layers, depending on how they contribute to the Cost. We have already seen this in the previous chapter.
The weights in each layer are adjusted in proportion to how each layers weights affected the Cost function.
This is by calculating the new weight by following the negative of the gradient of the Cost function - basically by gradient descent.
\[W^l_{new} = W^l_{old} - \eta \cdot \frac{\partial C_0}{\partial W^l}\]For adjusting the weight in the $(l-1)$ layer, we do similar
First calculate how the weight in this layer contributes to the final Cost or Loss
\[\frac{\partial C_0}{\partial W^{l-1}} = \frac{\partial C_0}{\partial a^{l-1}} \cdot \frac{\partial a^{l-1}}{\partial z^{l-1}} \cdot \frac{\partial z^{l-1}}{\partial W^{l-1}}\]and using this. Basically we are using Chain rule to find the partial differential using the partial differentials calculated in earlier steps.
\[W^{l-1}_{new} = W^{l-1}_{old} - \eta \cdot \frac{\partial C_0}{\partial W^{l-1}}\]Neural Net as a Composition of Vector Functions
Lets first look at a neural network as a composition of vector functions.
Imagine a simple neural network with 3 layers. It is essentially a composition of three functions:
A neural network is a composition of vector-valued functions, followed by a scalar-valued cost function:
\[C = \text{Cost}(a_3) a_3 = L_3(L_2(L_1(x)))\]Where $L_1$, $L_2$ and $L_3$ are the three layers of the network and
Each layer is defined as:
\[z_i = W_i a_{i-1} + b_i, \quad a_i = \sigma(z_i)\]And gradient descent is defined as:
\[W_{i_{new}} = W_{i_{old}} - \eta \cdot \partial C / \partial W_i\]Problem is to find the partial derivative of the loss function with respect to the weights at each layer.
To calculate how a change in the first layer’s weights ($W_1$) affects the final Cost ($C$), we have to trace the “path of influence” all the way through the network.
A nudge in $W_1$ changes the output of Layer 1. The change in Layer 1 changes the input to Layer 2. The change in Layer 2 changes the input to Layer 3. The change in Layer 3 changes the final Cost.
Mathematically, we multiply the derivatives (Linear Maps) of these links together:
We need to update weights of three layers
\[W_{1_{new}} = W_{1_{old}} - \eta \cdot \partial C / \partial W_1\] \[W_{2_{new}} = W_{2_{old}} - \eta \cdot \partial C / \partial W_2\] \[W_{3_{new}} = W_{3_{old}} - \eta \cdot \partial C / \partial W_3\]And for that we need to find $ \partial C / \partial W_1 $, $ \partial C / \partial W_2 $, $ \partial C / \partial W_3 $.
Lets write down the chain rule for each layer:
\[\frac{\partial C}{\partial W_1} = \frac{\partial C}{\partial L_3} \cdot \frac{\partial L_3}{\partial L_2} \cdot \frac{\partial L_2}{\partial L_1} \cdot \frac{\partial L_1}{\partial W_1}\] \[\frac{\partial C}{\partial W_2} = \frac{\partial C}{\partial L_3} \cdot \frac{\partial L_3}{\partial L_2} \cdot \frac{\partial L_2}{\partial W_2}\] \[\frac{\partial C}{\partial W_3} = \frac{\partial C}{\partial L_3} \cdot \frac{\partial L_3}{\partial W_3}\]Why is this written this way? By the chain rule, the derivative of a composition of functions is the product of the derivatives of the functions. It is thus easy to calculate the gradient of the loss with respect to the weights of each layer.
Lets calculate the gradient of the loss with respect to the weights of the first layer.
Notice something interesting?
-
To calculate $\frac{\partial C}{\partial W_3}$, we need $\frac{\partial C}{\partial L_3}$.
-
To calculate $\frac{\partial C}{\partial W_2}$, we need $\frac{\partial C}{\partial L_3} \cdot \frac{\partial L_3}{\partial L_2}$.
-
To calculate $\frac{\partial C}{\partial W_1}$, we need $\frac{\partial C}{\partial L_3} \cdot \frac{\partial L_3}{\partial L_2} \cdot \frac{\partial L_2}{\partial L_1}$.
We are re-calculating the same terms over and over again!
If we start from the Output (Layer 3) and move Backwards:
-
We calculate $\frac{\partial C}{\partial L_3}$ once. We use it to find the update for $W_3$.
-
We pass this value back to find $\frac{\partial C}{\partial L_2}$ (which is $\frac{\partial C}{\partial L_3} \cdot \frac{\partial L_3}{\partial L_2}$). We use it to find the update for $W_2$.
-
We pass that value back to find $\frac{\partial C}{\partial L_1}$. We use it to find the update for $W_1$.
This avoids redundant calculations and is why it’s called Backpropagation.
It is essentially Dynamic Programming applied to the Chain Rule.
The Backpropagation Algorithm Step-by-Step
Step 1: The Output Layer ($L_3$)
We want to find the gradient $\frac{\partial C}{\partial W_3}$. Using the Chain Rule: \(\frac{\partial C}{\partial W_3} = \frac{\partial C}{\partial a_3} \cdot \frac{\partial a_3}{\partial z_3} \cdot \frac{\partial z_3}{\partial W_3}\)
Let’s break it down term by term:
-
Derivative of Cost w.r.t Activation ($\frac{\partial C}{\partial a_3}$): For MSE $C = \frac{1}{2}(a_3 - y)^2$: \(\frac{\partial C}{\partial a_3} = (a_3 - y)\)
-
Derivative of Activation w.r.t Input ($\frac{\partial a_3}{\partial z_3}$): Since $a_3 = \sigma(z_3)$: \(\frac{\partial a_3}{\partial z_3} = \sigma'(z_3)\)
-
Derivative of Input w.r.t Weights ($\frac{\partial z_3}{\partial W_3}$): Since $z_3 = W_3 a_2 + b_3$: \(\frac{\partial z_3}{\partial W_3} = a_2\)
Combining them: We define the “error” term $\delta_3$ at the output layer as: \(\delta_3 = \frac{\partial C}{\partial z_3} = (a_3 - y) \odot \sigma'(z_3)\)
Note on $\odot$ (Hadamard Product): We use element-wise multiplication here because both $(a_3 - y)$ and $\sigma’(z_3)$ are vectors of the same size.
The Jacobian of an element-wise activation $\sigma$ is a diagonal matrix: \(\frac{\partial a}{\partial z} = \text{diag}(\sigma'(z))\)
So multiplying by it is the same as a Hadamard product: \(\text{diag}(\sigma'(z)) \, v = v \odot \sigma'(z)\)
We will see the Jacobian and Gradient Vector later.
So the gradient for the weights is: \(\frac{\partial C}{\partial W_3} = \delta_3 \cdot a_2^T\)
Note on Transpose ($a_2^T$): In backprop, we push gradients through a linear map $z = Wa + b$. The Jacobian w.r.t. $a$ is $W$, so the chain rule gives:
\[\frac{\partial C}{\partial a} = W^T \frac{\partial C}{\partial z}\]The transpose appears because we’re applying the transpose (adjoint) of the Jacobian to move gradients backward.
Result: We have the update for $W_3$.
\[W_{3_{new}} = W_{3_{old}} - \eta \cdot \partial C / \partial W_3\]Step 2: Propagate Back to $L_2$
Now we need to find the gradient for the second layer weights: $\frac{\partial C}{\partial W_2}$. Using the Chain Rule, we can reuse the error from the layer above: \(\frac{\partial C}{\partial W_2} = \frac{\partial C}{\partial z_2} \cdot \frac{\partial z_2}{\partial W_2} = \delta_2 \cdot a_1^T\)
But what is $\delta_2$ (the error at layer 2)? \(\delta_2 = \frac{\partial C}{\partial z_2} = \frac{\partial C}{\partial z_3} \cdot \frac{\partial z_3}{\partial z_2}\)
We know $\frac{\partial C}{\partial z_3} = \delta_3$. And since $z_3 = W_3 \sigma(z_2) + b_3$: \(\frac{\partial z_3}{\partial z_2} = W_3 \cdot \sigma'(z_2)\)
So, we can calculate $\delta_2$ by “backpropagating” $\delta_3$: \(\delta_2 = (W_3^T \cdot \delta_3) \odot \sigma'(z_2)\)
The Update Rule for Layer 2: \(\frac{\partial C}{\partial W_2} = \delta_2 \cdot a_1^T\)
Result: We have the update for $W_2$. \(W_{2_{new}} = W_{2_{old}} - \eta \cdot \frac{\partial C}{\partial W_2}\)
Step 3: Propagate Back to $L_1$
We repeat the exact same process to find the error at the first layer $\delta_1$. \(\delta_1 = (W_2^T \cdot \delta_2) \odot \sigma'(z_1)\)
The Update Rule for Layer 1: \(\frac{\partial C}{\partial W_1} = \delta_1 \cdot x^T\) (Recall that $a_0 = x$, the input).
Result: We have the update for $W_1$. \(W_{1_{new}} = W_{1_{old}} - \eta \cdot \frac{\partial C}{\partial W_1}\)
Summary
So, Backpropagation is the efficient execution of the Chain Rule by utilizing the linear maps of each layer in reverse order.
- It computes the local linear map (Jacobian) of a layer.
- It takes the incoming gradient vector from the future layer.
- It performs a Vector-Jacobian Product to pass the gradient to the past layer.
Next Backpropagation with Matrix Calculus